
R2D2 [ICLR 2019]: много железа + смекалка = прорыв
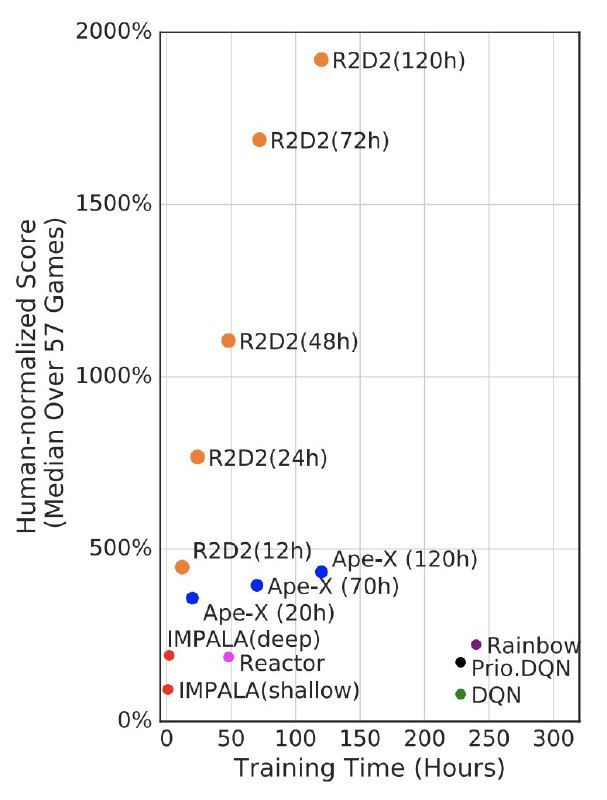
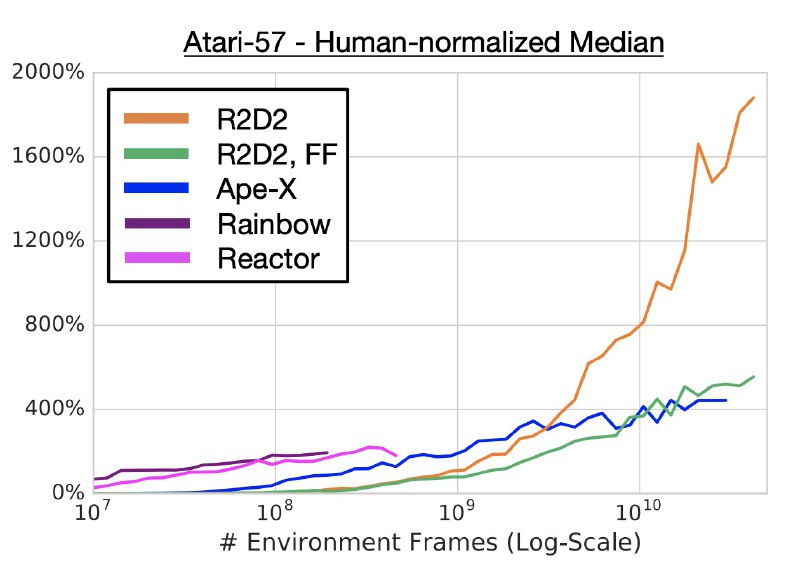
В данной работе мы наблюдаем революцию в итоговой производительности - если посчитать очки в каждой из 57 игр Атари, нормализовать их на человеческий результат и взять медиану, получается 2000%. У ближайшего конкурента 400%, а у далёкого предка только 50%.
Всё благодаря комбинации нескольких удачных решений:
1) Под капотом теперь LSTM, которую учат на сохранённых траекториях агента в среде, грамотно обходя проблему холодного старта скрытого состояния LSTM.
2) Огромное количество "воркеров", собирающих данные - алгоритмы в RL любят, когда данные для обучения собраны свежей стратегией и их много. Особенно, когда у вас LSTM.
3) Набор хорошо закрепившихся RL-специфичных улучшений, про которые я не рассказывал.
Для обучения были собраны десятки миллиардов кадров. Без симулятора такой подход не имеет смысла.
Картинки: на первой производительность алгоритмов в зависимости от времени обучения в часах, на второй - в зависимости от количества кадров (угадайте, какая из них в аппендиксе).
@knowledge_accumulator
В данной работе мы наблюдаем революцию в итоговой производительности - если посчитать очки в каждой из 57 игр Атари, нормализовать их на человеческий результат и взять медиану, получается 2000%. У ближайшего конкурента 400%, а у далёкого предка только 50%.
Всё благодаря комбинации нескольких удачных решений:
1) Под капотом теперь LSTM, которую учат на сохранённых траекториях агента в среде, грамотно обходя проблему холодного старта скрытого состояния LSTM.
2) Огромное количество "воркеров", собирающих данные - алгоритмы в RL любят, когда данные для обучения собраны свежей стратегией и их много. Особенно, когда у вас LSTM.
3) Набор хорошо закрепившихся RL-специфичных улучшений, про которые я не рассказывал.
Для обучения были собраны десятки миллиардов кадров. Без симулятора такой подход не имеет смысла.
Картинки: на первой производительность алгоритмов в зависимости от времени обучения в часах, на второй - в зависимости от количества кадров (угадайте, какая из них в аппендиксе).
@knowledge_accumulator
tg-me.com/knowledge_accumulator/24
Create:
Last Update:
Last Update:
R2D2 [ICLR 2019]: много железа + смекалка = прорыв
В данной работе мы наблюдаем революцию в итоговой производительности - если посчитать очки в каждой из 57 игр Атари, нормализовать их на человеческий результат и взять медиану, получается 2000%. У ближайшего конкурента 400%, а у далёкого предка только 50%.
Всё благодаря комбинации нескольких удачных решений:
1) Под капотом теперь LSTM, которую учат на сохранённых траекториях агента в среде, грамотно обходя проблему холодного старта скрытого состояния LSTM.
2) Огромное количество "воркеров", собирающих данные - алгоритмы в RL любят, когда данные для обучения собраны свежей стратегией и их много. Особенно, когда у вас LSTM.
3) Набор хорошо закрепившихся RL-специфичных улучшений, про которые я не рассказывал.
Для обучения были собраны десятки миллиардов кадров. Без симулятора такой подход не имеет смысла.
Картинки: на первой производительность алгоритмов в зависимости от времени обучения в часах, на второй - в зависимости от количества кадров (угадайте, какая из них в аппендиксе).
@knowledge_accumulator
В данной работе мы наблюдаем революцию в итоговой производительности - если посчитать очки в каждой из 57 игр Атари, нормализовать их на человеческий результат и взять медиану, получается 2000%. У ближайшего конкурента 400%, а у далёкого предка только 50%.
Всё благодаря комбинации нескольких удачных решений:
1) Под капотом теперь LSTM, которую учат на сохранённых траекториях агента в среде, грамотно обходя проблему холодного старта скрытого состояния LSTM.
2) Огромное количество "воркеров", собирающих данные - алгоритмы в RL любят, когда данные для обучения собраны свежей стратегией и их много. Особенно, когда у вас LSTM.
3) Набор хорошо закрепившихся RL-специфичных улучшений, про которые я не рассказывал.
Для обучения были собраны десятки миллиардов кадров. Без симулятора такой подход не имеет смысла.
Картинки: на первой производительность алгоритмов в зависимости от времени обучения в часах, на второй - в зависимости от количества кадров (угадайте, какая из них в аппендиксе).
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/24